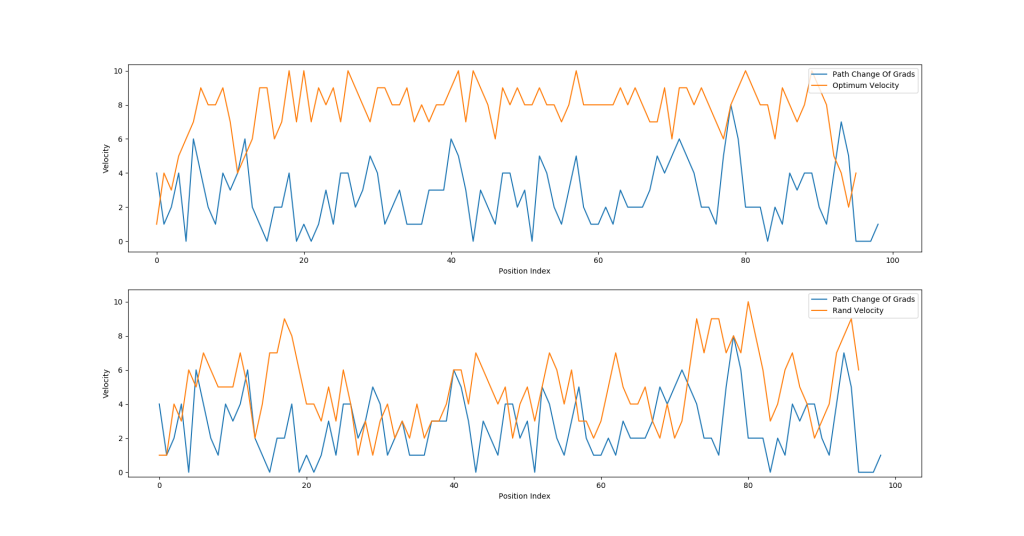
The inspiration for this project was to develop a novel velocity planning algorithm that considered the passenger comfort as a primary parameter given finite knowledge of the terrain ahead of the vehicle. We implemented Model-Free Reinforcement methods, specifically SARSA and Q-Learning as well as Dyna, a Model Based Reinforcement Learning method.
We managed to achieve a 108% improvement over random policy velocity profiles using iterative Q-Learning.